Yesterday we had an issue with one of our 100 megabit connections to the outside world, which runs most of our WAN traffic. I’m posting this to try and convince ya’ll on the interwebs to double-check my thinking.
So, here’s the timeline:
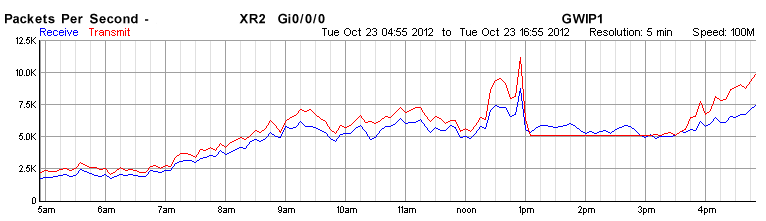
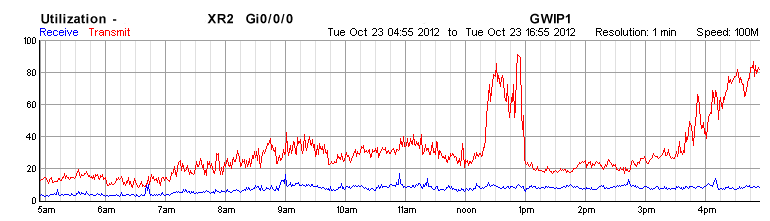
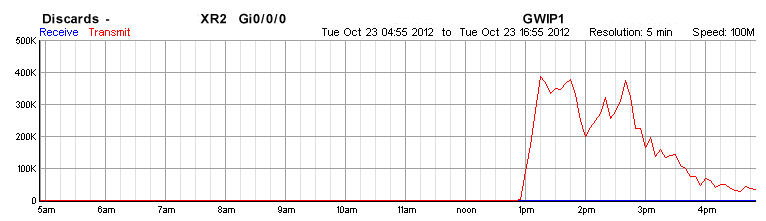
- Approximately 1305 outbound usable bandwidth from our active GWIP link dropped to an average of ~20Mbit/second. The maximum outbound packet rate sat on approximately 5000 packets/second. Inbound data was not affected.
- Investigations started at approximately 1330, it was originally believed that power brownouts which affected many sites in the SEQ region at approximately 1215-1220 could have been affecting services.
- At approximately 1415pm a job was logged with The Vendor.
- The job was escalated within The Vendor to Tier2 at approximately 1500, and I spoke with some Vendor reps about the escalation approximately ten minutes later.
- As of approximately 1515, packet rates started to rise and outbound bandwidth started to increase.
- I spoke with their tech at approximately 16:15; he advised that during the impact to services we were over-utilizing the link.
- The Vendor claims that due to the fact that their systems show 5 minute averages and ours 1 minute, this explains the 80Mbit/second disparity in traffic displayed on our respective systems.
Other facts:
- Our Cisco router limits outbound bandwidth to 95,000,000 bits per second leaving the interface (using the shape policing method).
- Due to packet overheads inherent in GWIP connections, high packet transmit rates might cause an over-utilization condition but as packet rates stayed at approximately 5000/second we believe this to be incredibly unlikely as a cause.
Our data
Yesterday we had an issue with one of our 100 megabit connections to the outside world, which runs most of our WAN traffic. I’m posting this to try and convince ya’ll on the interwebs to double-check my thinking.
So, here’s the timeline:
- Approximately 1305 outbound usable bandwidth from our active GWIP link dropped to an average of ~20Mbit/second. The maximum outbound packet rate sat on approximately 5000 packets/second. Inbound data was not affected.
- Investigations started at approximately 1330, it was originally believed that power brownouts which affected many sites in the SEQ region at approximately 1215-1220 could have been affecting services.
- At approximately 1415pm a job was logged with The Vendor.
- The job was escalated within The Vendor to Tier2 at approximately 1500, and I spoke with some Vendor reps about the escalation approximately ten minutes later.
- As of approximately 1515, packet rates started to rise and outbound bandwidth started to increase.
- I spoke with their tech at approximately 16:15; he advised that during the impact to services we were over-utilizing the link.
- The Vendor claims that due to the fact that their systems show 5 minute averages and ours 1 minute, this explains the 80Mbit/second disparity in traffic displayed on our respective systems.
Other facts:
- Our Cisco router limits outbound bandwidth to 95,000,000 bits per second leaving the interface (using the shape policing method).
- Due to packet overheads inherent in GWIP connections, high packet transmit rates might cause an over-utilization condition but as packet rates stayed at approximately 5000/second we believe this to be incredibly unlikely as a cause.
Vendor’s data
According to the vendor this is traffic at the switch port our link is connected to.
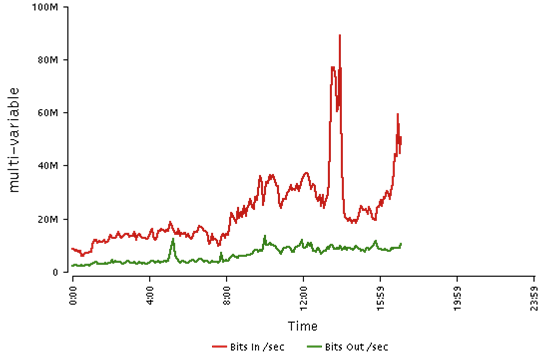
So… suggestions anyone?